
大前端
Why Hono Is the Web Framework You Should Try in 2025
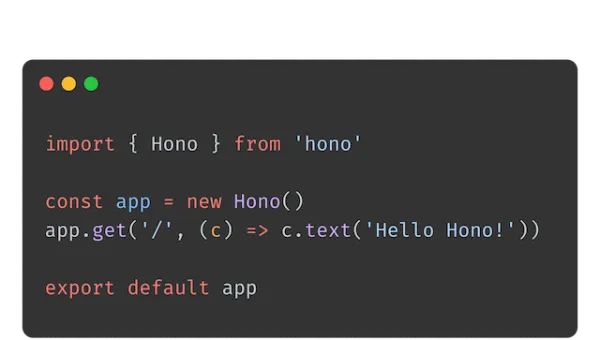
Why Hono Is the Web Framework You Should Try in 2025 If you’re a developer looking for a fast, flexible, and modern web framework, let me introduce you to Hono. I’ve been building web apps for years, and Hono has quickly become one of my go-to tools for




